よくある質問
テストの実行速度が非常に遅い
この`@wdio/ocr-service`を使用する場合、テストの高速化を目的とするのではなく、Web/モバイルアプリで要素の特定が困難な場合に、より簡単な方法で要素を特定するために使用します。そして、私たち全員が願わくば知っているように、何かを望むときには、何か他のものを失います。**しかし....**、`@wdio/ocr-service`を通常よりも高速に実行する方法があります。詳細についてはこちらをご覧ください。
このサービスのコマンドをデフォルトのWebdriverIOコマンド/セレクターと一緒に使用できますか?
はい、コマンドを組み合わせてスクリプトをさらに強力にすることができます!可能な限りデフォルトのWebdriverIOコマンド/セレクターを使用し、一意のセレクターが見つからない場合、またはセレクターが壊れやすくなる場合にのみ、このサービスを使用することをお勧めします。
テキストが見つかりません。なぜですか?
まず、このモジュールでのOCR処理の仕組みを理解することが重要です。そのため、このページをお読みください。それでもテキストが見つからない場合は、次のことを試してみてください。
画像領域が大きすぎる
モジュールがスクリーンショットの広い領域を処理する必要がある場合、テキストが見つからないことがあります。コマンドを使用するときに haystack を指定することで、より小さな領域を指定できます。 haystack の指定をサポートするコマンドについては、コマンドをご確認ください。
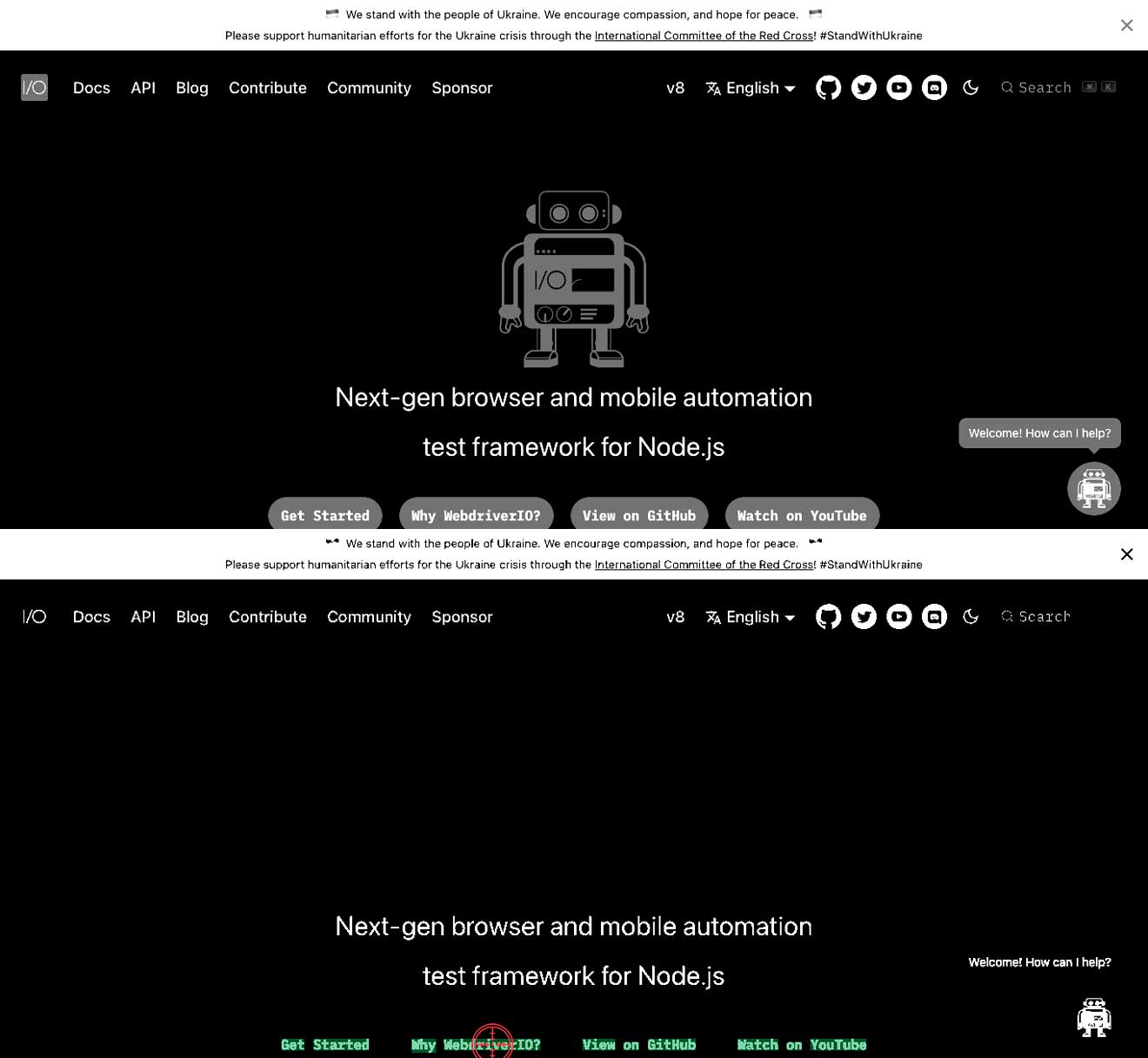
テキストと背景のコントラストが正しくない
これは、白い背景に明るいテキスト、または暗い背景に暗いテキストがあることを意味します。これにより、テキストが見つからない場合があります。以下の例では、`Why WebdriverIO?`というテキストが白で、灰色のボタンで囲まれていることがわかります。この場合、`Why WebdriverIO?`というテキストは見つかりません。特定のコマンドのコントラストを上げることで、テキストが見つかり、クリックできるようになります(2番目の画像を参照)。
await driver.ocrClickOnText({
haystack: { height: 44, width: 1108, x: 129, y: 590 },
text: "WebdriverIO?",
// // With the default contrast of 0.25, the text is not found
contrast: 1,
});
要素はクリックされるのに、モバイルデバイスのキーボードが表示されないのはなぜですか?
これは、クリックが長すぎると判断され、ロングタップと見なされる一部のテキストフィールドで発生する可能性があります。 `ocrClickOnText` および `ocrSetValue` で `clickDuration` オプションを使用して、これを軽減できます。 こちら を参照してください。
このモジュールは、WebdriverIOが通常行うように、複数の要素を返すことができますか?
いいえ、現在これは不可能です。モジュールが指定されたセレクターに一致する複数の要素を見つけた場合、自動的に一致スコアの最も高い要素が検索されます。
このサービスで提供されるOCRコマンドを使用して、アプリを完全に自動化できますか?
私はそれをやったことがありませんが、理論的には可能であるはずです。成功したらお知らせください☺️。
`{languageCode}.traineddata`という名前の追加ファイルが表示されます。これは何ですか?
`{languageCode}.traineddata` は、Tesseract で使用される言語データファイルです。選択した言語のトレーニングデータが含まれており、Tesseract が英語の文字と単語を効果的に認識するために必要な情報が含まれています。
`{languageCode}.traineddata`の内容
ファイルには一般的に以下が含まれています
- **文字セットデータ:** 英語の文字に関する情報。
- **言語モデル:** 文字が単語を形成し、単語が文を形成する方法の統計モデル。
- **特徴抽出器:** 文字認識のために画像から特徴を抽出する方法に関するデータ。
- **トレーニングデータ:** 大量の英語テキスト画像で Tesseract をトレーニングすることによって得られたデータ。
`{languageCode}.traineddata` が重要な理由
- **言語認識:** Tesseract は、これらのトレーニング済みデータファイルに依存して、特定の言語のテキストを正確に認識および処理します。 `{languageCode}.traineddata` がないと、Tesseract は英語のテキストを認識できません。
- **パフォーマンス:** OCR の品質と精度は、トレーニングデータの品質に直接関係しています。正しいトレーニング済みデータファイルを使用すると、OCR プロセスが可能な限り正確になります。
- **互換性:** プロジェクトに `{languageCode}.traineddata` ファイルが含まれていることを確認することで、異なるシステムまたはチームメンバーのマシン間で OCR 環境を複製しやすくなります。
`{languageCode}.traineddata` のバージョン管理
バージョン管理システムに `{languageCode}.traineddata` を含めることをお勧めします。理由は次のとおりです。
- **一貫性:** すべてのチームメンバーまたはデプロイメント環境がトレーニングデータのまったく同じバージョンを使用することを保証し、異なる環境間で一貫した OCR 結果につながります。
- **再現性:** このファイルをバージョン管理に保存すると、後日または別のマシンで OCR プロセスを実行するときに結果を再現しやすくなります。
- **依存関係管理:** バージョン管理システムに含めることで、依存関係の管理に役立ち、セットアップまたは環境構成にプロジェクトを正しく実行するために必要なファイルが含まれるようにします。
テストを実行せずに画面上で見つかったテキストを簡単に確認する方法はありますか?
はい、CLIウィザードを使用できます。ドキュメントはこちらにあります。
